
Post-Training LLMs: When to Use SFT, DPO, PPO, and GRPO
Understanding when to use supervised fine-tuning vs reinforcement learning for LLMs - with infrastructure guidance and decision frameworks

Choosing between post-training techniques—supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and reinforcement learning methods like PPO and GRPO - is a tricky decision in LLM development.
The literature is full of algorithmic details. What it lacks is decision-making guidance: Does my problem need supervised fine-tuning or reinforcement learning? What about infrastructure requirements?
I could have just asked LLM’s to summarize everything, but I wanted something deeper. I wanted to build the muscle memory to look at a problem and know: that’s the right technique, here’s why, and here’s what it’ll cost.
This article is that mental model. Let’s build intuition for post-training—not just what each method does, but when it’s the right choice.
The Four Paradigms of Post-Training
Below table summarizes each paradigm, highlighting its purpose, potential applications and associated techniques.
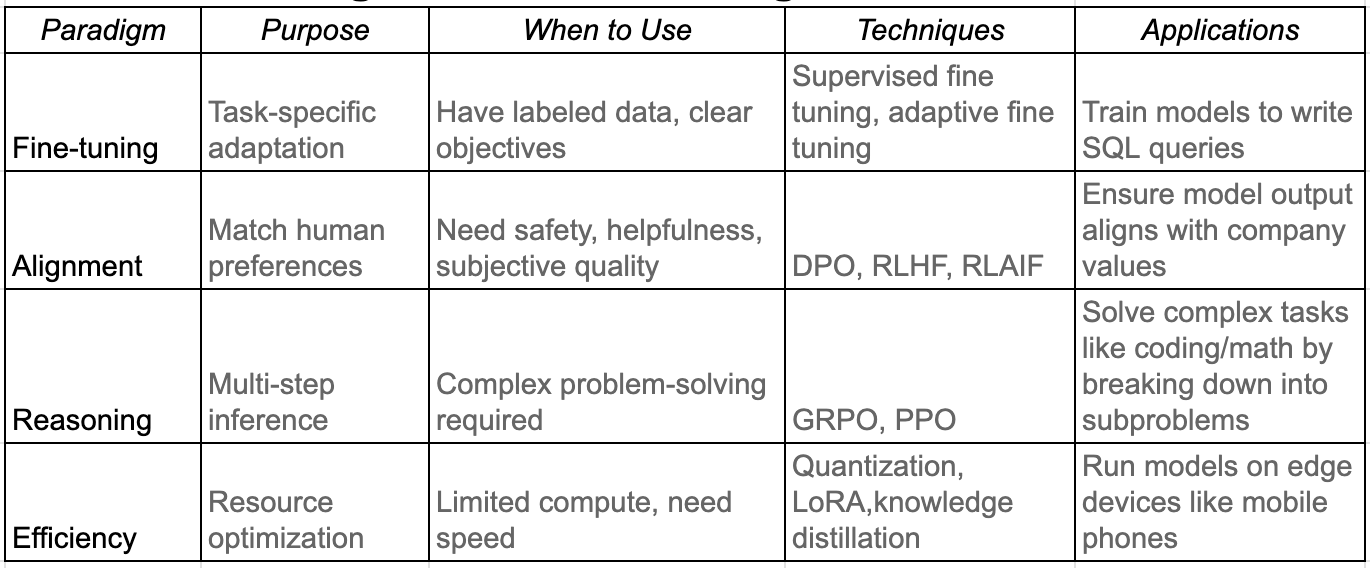
Next we take a look at each of the paradigms and the associated algorithms.
Supervised Fine-Tuning (SFT)
SFT trains on labeled pairs (x_i, y_i) from dataset D, where x_i is an input prompt and y_i is the desired output. The model minimizes cross-entropy loss between its generated tokens and the target sequence from the dataset through autoregressive generation.
Essentially, the model learns: “When you see input like x, produce output like y.”
When to use it:
Clear input-output pairs (Q&A datasets, code with tests, translation pairs)
Tasks with objective correctness (factual accuracy, code functionality)
Format compliance (JSON output, specific response structure)
Domain adaptation with example demonstrations
Key insight: SFT excels at imitation - teaching the model how to respond. But it struggles with subjective preferences. If you can’t deterministically specify the correct answer, SFT hits its limits because it has no notion of better vs. worse only correct vs. incorrect
Real-world example: Fine-tuning model to provide structured responses like JSON
Alignment: Learning from Comparisons using Direct Preference Optimization (DPO)
DPO trains on triplets (x_i, y_w, y_l) where y_w is the preferred response and y_l is rejected response to input x_i. Instead of showing the model what to do, you show it comparisons: “Response A (y_w) is better than Response B (y_l).”
DPO bypasses the need for a separate reward model by directly optimizing the policy to prefer chosen responses over rejected ones, with a KL penalty to prevent drift from the base model.
When to use it:
Tasks involve subjective quality (helpfulness, tone, style)
You can rank responses but can’t write the perfect answer
You want alignment without RL complexity
You have preference data (human rankings, AI feedback)
Key insight: DPO excels when quality is comparative rather than absolute. It’s easier to say “A is better than B” than to write the perfect response from scratch.
Real-world example: Making a chatbot more helpful by training on pairs where humans preferred one response style over another.
Reasoning: Group Relative Policy Optimization (GRPO)
So far, the problem setting involves a single step process - Given an input token sequence x, produce desired output y.
However, reasoning is often modeled as a multi step process that requires planning. To achieve the desired output y - the model produces multiple intermediate states (s_i) taking an action (a_i) at each state i.
Traditional approaches for solving such settings like Proximal Policy Optimization (PPO) suffer from substantial computational demands due to the need to train a value model for predicting rewards.
GRPO simplifies this by eliminating the value model entirely. For each prompt, it samples multiple outputs (typically 8-16 completions), scores them all, and uses these scores to compute advantages directly
When to use it:
Want RL benefits without value model complexity
Can afford multiple sampling per prompt
Reward function is reliable across samples
Need faster iteration than PPO
Real-world example: DeepSeek-R1 using GRPO with 16 samples per prompt to train reasoning capabilities. This proved more cost efficient than maintaining a separate critic.
Efficiency: Quantization and Low Rank Adaptation (LoRA)
Techniques like quantization and low rank adaptation (LoRA) allow executing the above algorithms in a compute constrained setting. They reduce memory by 5-12× with minimal quality degradation in most tasks.
Quantization: Use a lower floating point memory representation reducing vRAM usage
LoRa: The trained weight matrix (W) can be broken into low ranked matrices (A, B) thus reducing the number of trained parameters.
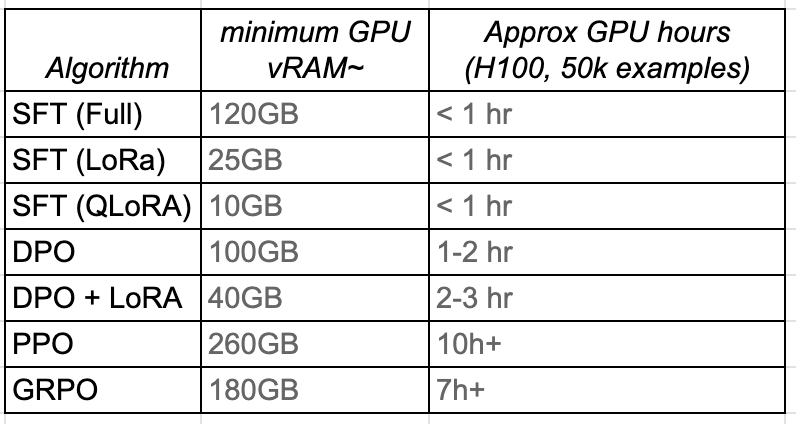
Infrastructure Reality Check
Understanding infrastructure requirements is critical for practical deployment. Here’s what each method requires for a 7B parameter model:
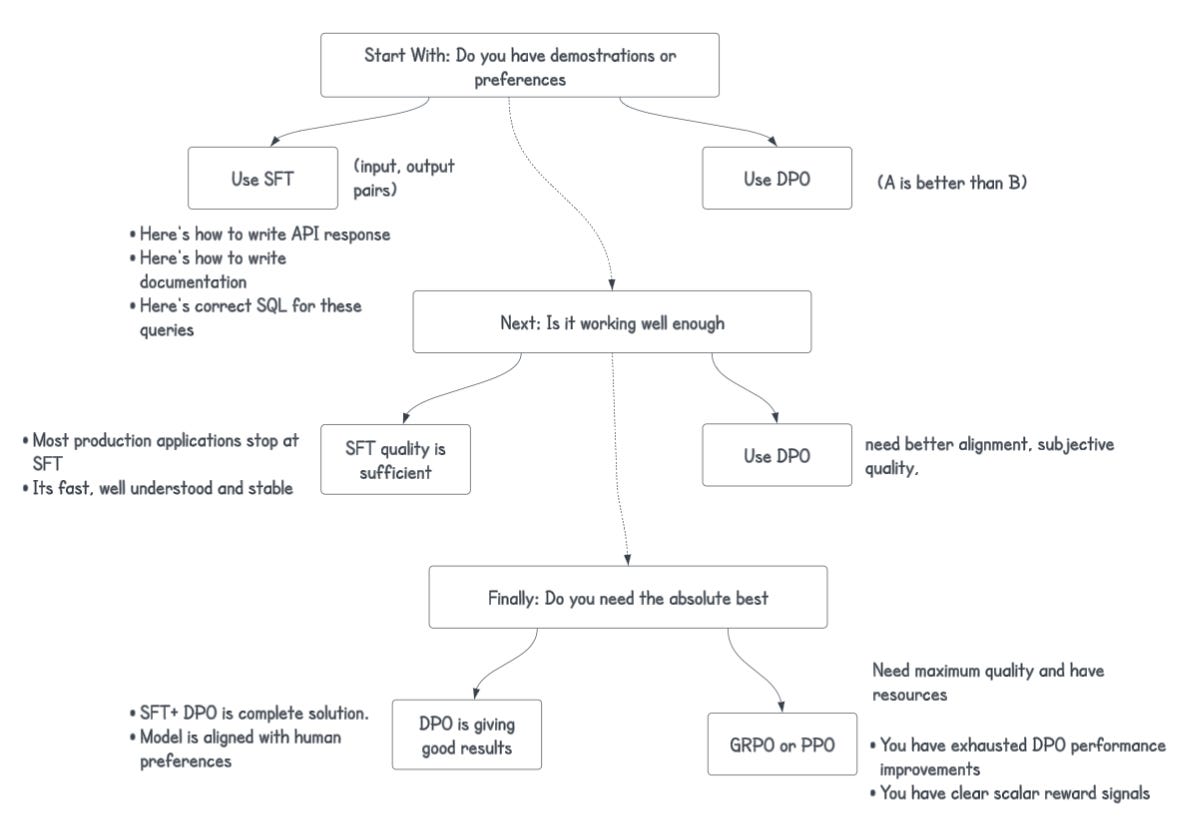
Conclusion: Choosing the right approach for your use case
Further Reading
Foundational Papers:
A Survey on Post-training of Large Language Models: (Guiyao Tie et al., 2025)
SFT: “Language Models are Few-Shot Learners” (Brown et al., 2020)
LoRA: “LoRA: Low-Rank Adaptation of Large Language Models” (Hu et al., 2021)
QLoRA: “QLoRA: Efficient Finetuning of Quantized LLMs” (Dettmers et al., 2023)
DPO: “Direct Preference Optimization” (Rafailov et al., 2023)
PPO: “Proximal Policy Optimization Algorithms” (Schulman et al., 2017)
GRPO: “DeepSeek-R1” technical report (2025)
Regarding the topic of the article, what if the clear input-output pairs needed for SFT proove less robust for certain nuanced tasks than initially assumed?